I believed them in 2017 and got a Vega64. ROCm was never propertly integrated into distributions, frameworks or applications, and once it at least trickled in into distributions in some limited form, Vega support is already being deprecated.
For me to try again ROCm, the bar will be significantly higher.
More users mean more angry emails kicking the driver team and Lisa Su in the butt. I personally gave up on them and my only bet is RustiCL becoming stable enough to become a widely used standard.
People are doubtful of this because AMD has halfassed it over and over in the past, but I do see a lot of desire among MS, google, and AMZ to break nvidia's monopoly on gpu compute. I don't know that ROCm will be the thing that does that but I do think some open source alternative will gain steam. Google is furthest along here with their tensor cores and the support for that, but I could easily see a group rallying behind AMD hardware as the only gpu manufacturer out there that has serious experience with HPC.
The way I see it is its now or never for AMD. with the amount of money pouring into AI & gpgpu compute if AMD cant even get it right now then they will never be able to do it as nvidia pulls away further and further away. its a shame because their gpus were actually better for this type of compute beginning with bitcoin mining but for some reason they never foresaw this even though nvidia has been investing steadily in CUDA for about a decade.
> do see a lot of desire among MS, google, and AMZ to break nvidia's monopoly on gpu compute
They are all implementing XLA-compatible accelerators where the software is mostly opensource and the hardware is not.
> but I could easily see a group rallying behind AMD hardware
I strongly believe that ship has sailed and sunk to the bottom of the ocean. MS/Meta/Google/Amazon won't hitch their trailer to another platform that they don't control. They will invest more and more into custom silicon which offers one more way to do vendor lock-in while also giving them more control over pricing strategies.
Right now the issue is that they can't buy enough Nvidia GPUs to meet demand and Nvidia is itself forced to deal with TSMC.
Can confirm, I can run PyTorch with ROCm just fine on 6900xt and 7900xt on Debian. The 7900xt does require the nightly build of PyTorch (for ROCm >=5.5 support, I run 5.6) in order to automatically get the gfx1100_42.ukdb miopen kernel. I must specify which gpu and which miopen kernel when starting python. My device 0 is the 7900xt and device 1 is 6900xt, so for each I run the corresponding commands:
GFX 10.3.0 for gfx1031 and GFX 11.0.0 for gfx1100, but be aware that the kernel is tied to the series, so even thought the 6700 is technically gfx1031, it uses the gfx1030 kernel, same thing if you use a newer rx 7000 series.
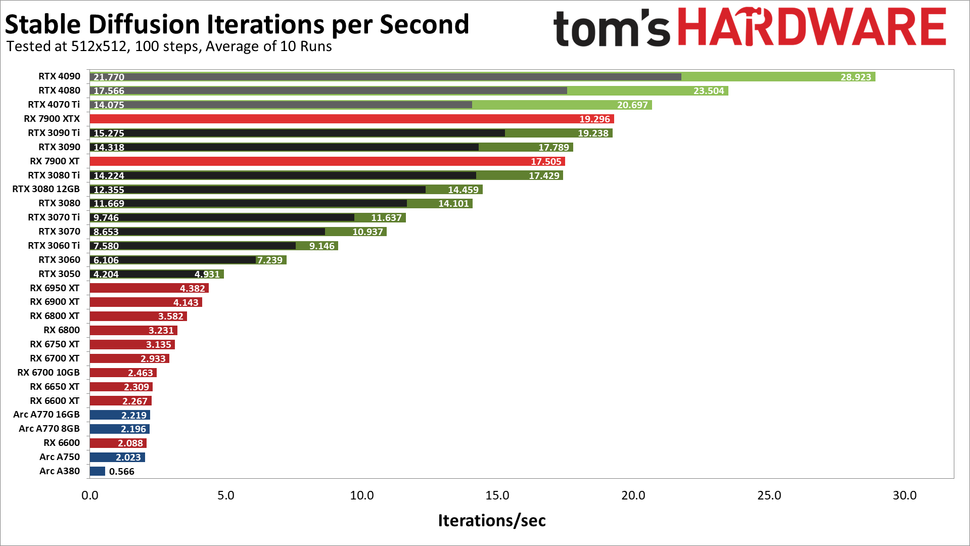
Seems that specific benchmark is deprecated. For me, I do get around 15 iterations/second on my 7900xt when running "stabilityai/stable-diffusion-2-1-base" for 512x512. I get around 10 iterations/second when running "stabilityai/sd-x2-latent-upscaler" to upscale a 512x512 to 1024x1024.
Here is a link to a tom's HARDWARE stable diffusion benchmark from January to get a rough idea on where various cards fit in for that use case:
Sure, some people say this is possible, but in my experience this is practically impossible.
Maybe that was a failure on my part; but I never was able to get it to work reliably. For a certain combination of versions of tools + some hacks, you can make it work. Then it breaks with the first update to any of those tools.
Nice -- does anyone one know if this applies to the Steam Deck? Maybe not a game changer, but certainly a neat thing for us to play around with. (I also have a 4gb RX 570, but I'm fairly certain the Steam Deck is better, yes?)
I would expect ROCm to work just fine with with Steam Deck. Given that the Steam Deck apparently uses gfx1033. So you probably need to specify the environment variable HSA_OVERRIDE_GFX_VERSION=10.3.0 and corresponding gfx1030_20.ukdb miopen kernel. I do not own a Steam Deck, but I do have another RDNA2 card, an RX 6700XT, which uses the similar gfx1031 ISA, which works just fine. While I don't have a RX 570, I do have a RX 480 which is also gfx803 like your RX 570 which should technically work, however don't expect much in performance or capability, as most work loads expect more than your 4GB of vram and much more compute power. You will also would need to use older versions of ROCm as well as these older cards are deprecated; I think I had to use ROCm <=4.3.1 if I remember correctly. What did you want to run specifically?
AMD continues to sabotage itself with their terrible GPU compute support. I don't understand why it's so hard for them to pick a single API and support it on all GPUs and on all major platforms (Linux, Windows).
It's no wonder why NVIDIA's market cap is so much higher.
Also, once they have decent consumer ML support, they could release a card that has a merely OK-ish GPU, but double the memory of nvidia counterparts (e.g. 32 or 48 GiB, or find some way to allow you to plug in your own memory), and it'd be crazy popular as well I think, because memory is the real limitation to what you can do, for inference at least!
That's true although they will be concerned with product segmentation as well. Pro GPUs are where the margins are so they will be careful not to let their consumer gear cannibalise them too much. Nvidia seemingly does this by intentionally limiting VRAM on consumer parts where software support is more or less equivalent for CUDA so you'd imagine AMD could end up following the same path.
Yeah this is why competition is good. It's possible that AMD might just decide "fuck segmentation let's undercut Nvidia and steal marketshare" like they did with the first and second gen Threadripper / Threadripper PRO (later generations priced the Threadripper PRO's at "fuck you, just buy Epyc" prices while gatekeeping some key features from the non PROs).
Games do use GPGPU through DirectX12 compute shaders.
Maybe Vulkan compute shaders if cross-platform capability is desired.
Video Games already have a huge pipeline of GPU-compute setup for vertex / pixel shaders, geometry shaders and more. Throwing a DirectX Compute Shader / Vulkan Shader on top is no biggie. But this is a lot of cruft to add to a non-video game (gotta initialize DirectX or Vulkan graphics just to start running compute shaders, and ignoring the default vertex/pixel shaders that the APIs are designed for...)
> most notably realistic physics simulations
Physics simulation is a dead-end. There's no reason to do physics on GPU, because copying the data from CPU->GPU is slow, and GPU -> CPU is slower.
By the time all the copying, calculating, and copying back is done, the GPU-physics data is obsolete and the CPU might as well have run it locally in L3 cache instead.
I think there's a chance that GPGPU video games could exist, but the graphics would have to be delayed relative to the physics simulation.
Time X starts running a step of the physics simulation. Time X+1 the physics simulation copies back to CPU, and gives CPU-time to finalize the results. Time X+2 CPU copies the data into the Vertex/Pixel shaders for rendering to the user.
Would be nice if I could pull more nodes per second on LeelaChessZero with my AMD card on Linux. Had to go to war with my drivers just to get OpenCL to clock above 1k, which it does go beyond now....after the war.
I was able to set up ROCm on my Arch system w/ RX 6600 relatively painlessly, and that was a few months ago. Honestly, I had no idea the support was otherwise this bad (at least, according to other comments). Using stable diffusion, for the most part it "just worked" barring some initial slight tweaks.
how will it unify its RDNA and CDNA into ROCm with consistent APIs are the core questions to me, i.e. to merge AI and graphic-rendering at software level, similar to what CUDA does.
{kind=link}
I believed them in 2017 and got a Vega64. ROCm was never propertly integrated into distributions, frameworks or applications, and once it at least trickled in into distributions in some limited form, Vega support is already being deprecated.
For me to try again ROCm, the bar will be significantly higher.