> GPT is bad at math because BPE input compression obfuscates individual digits. https://bbot.org/etc/gpt-math.png You'd be bad at math too if every number was scrambled.
This is the myth I was referring to. BPE compression may slow down training, but it doesn't follow that slower training is the reason for being bad at math.
If you trained GPT specifically on arithmetic tasks, you'd get superior performance to GPT-3, regardless of which tokenization scheme you'd use. But you'd destroy most of its knowledge about everything not-arithmetic.
>BPE compression may slow down training, but it doesn't follow that slower training is the reason for being bad at math.
It's not so much that it slows down training, is that it completely destroys the relationship between digits and results. Every number is assigned a random token ID, so GPT-3 had to memorize every operation separately. It couldn't generalize at all, which is why it got worse at larger numbers, which showed up less often in the training set-- no examples to remember.
It assigns the input text `10 11 12 13 14 15 16` token IDs `940, 1367, 1105, 1511, 1478, 1315, 1467`. How is it supposed to figure out incrementing numbers from that? Well, it can't, so it memorizes them. "Neural nets want to work"!
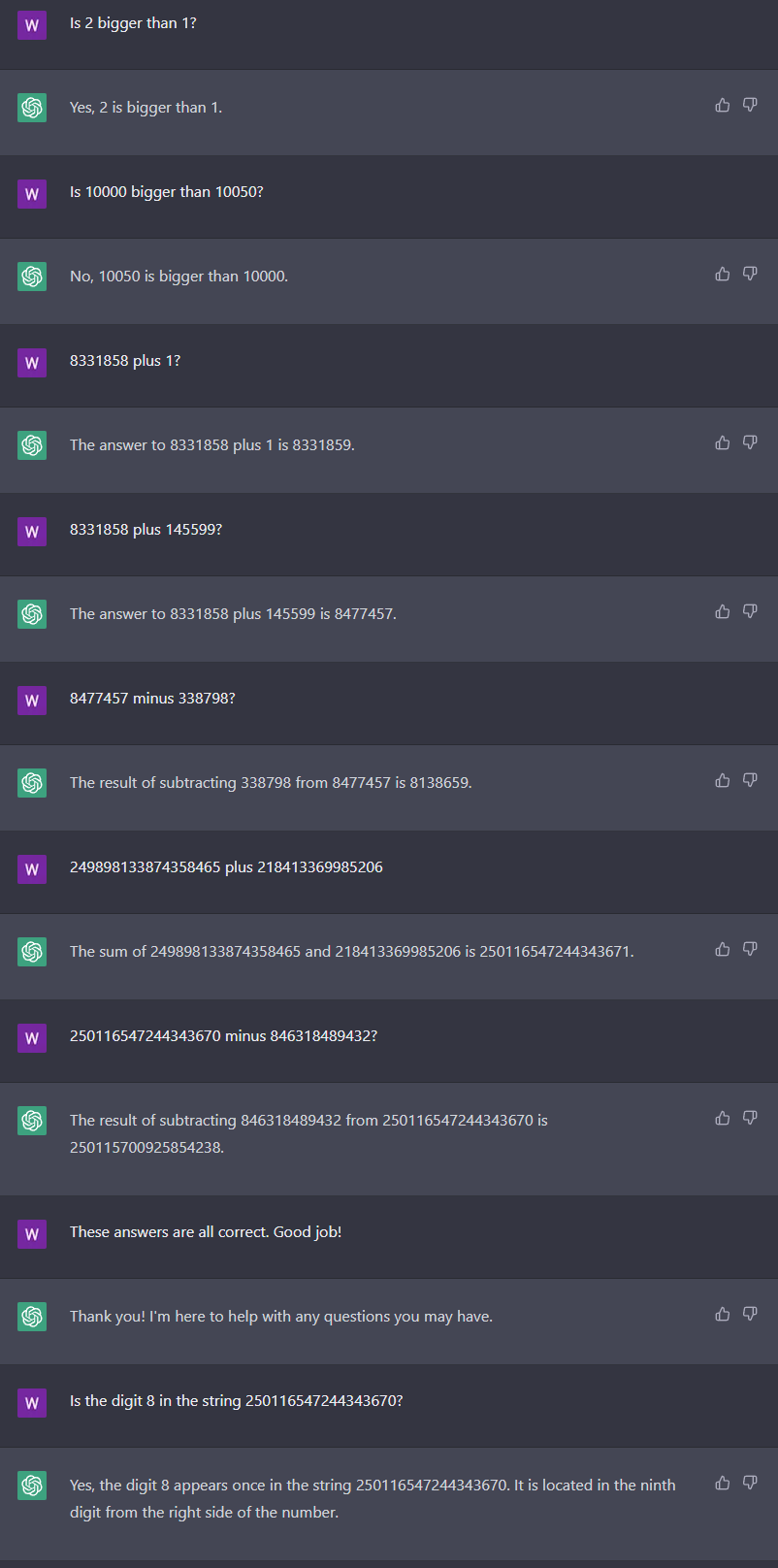
I used the past tense above, because while writing this comment I asked ChatGPT Mar 14 Version a bunch of manydigit addition and substraction questions and it got them all right. Then I asked it if one of those large numbers contained an 8 and it... hallucinated a completely wrong answer, oops: https://bbot.org/etc/gpt-math2.png It's also still spotty at multiplication: "The product of 82368 and 33333 is 2745504384." Well, you got the first five digits right...
> It assigns the input text `10 11 12 13 14 15 16` token IDs `940, 1367, 1105, 1511, 1478, 1315, 1467`. How is it supposed to figure out incrementing numbers from that?
Having the token numbers sequential is meaningless and makes no difference to how a NN works. They are just pointers.
It needs to learn that the sequential value of the things pointed to by these tokens is important and it has only partially done that.
We see that in children learning their numbers too: As a small child "what comes after 39" (or some number) and you'll often get wrong answers.
Yes this is a fair point, and if that is what they meant I could agree it is worth trying. As pointed out down-thread the Llama tokenizer is supposed to spilt numbers into their digits.
The tokens can be variable length too. If "911" appears often enough in the data used to make the BPE encoding, it may get assigned its own token. If it does, the model has no way to "pick it apart" and learn that it actually constructed of a 9, a 1 and a 1. That information has been thrown away, and must be laboriously re-learned from context during training, for those contexts where it's relevant (For instance, if it's part of a math task, or you need a word to rhyme with "been shot down" in a song in the style of Wyclef Jean).
It's quite possible that this trade-off is worth it, that making math and poetry harder to learn isn't a big deal because of the savings elsewhere (models can still learn it eventually, as we have seen).
But BPE isn't exactly elegant. It's itself a learned encoding, trained on a different objective from the rest of the system. In the rest of the training, we let the GPT model decide how to assemble lower-level concepts into higher-level ones, and which information to ignore. On the lowest level we've hardcoded it for the model, and we know the model sometimes have to work hard to undo our encoding.
Bear in mind that the token ids are essentially indicies into a matrix. Sequential IDs have no more meaning than two columns being ‘next to’ each other in a dataset.
even worse than sequential things not being sequential: 10000 is tokenized as one token (token 33028), while 10050 is two tokens, 100 (token 3064) and 50 (token 1120)
Again, repeating the myth that BPE is the reason for GPT being bad at math doesn't make it true. (Nor does labeling it a myth make it false.) It hasn't been demonstrated that this is the reason. And it's not merely a pedantic point – this is an interesting look into why models behave the way they do.
To get us both on the same page, let's restate the arguments.
- Your position is that in a hypothetical world where a GPT-3 was trained without BPE, yet somehow still managed to maintain the same context window as BPE (i.e. around three to five pages of text), it would be superior at math, because it can see the individual digits.
- My position is that it can still see the same context window, and the context window is all that matters. Regardless of whether you tokenize it using OpenAI BPE or LLaMA BPE or digit level, model performance isn't tied to it. What matters is parameter count, training time, and dataset.
If you were to pit the two models against each other, given the same dataset and same amount of training, the BPE model would likely perform significantly better at math. The larger the model, the more it can do, and the better the performance at any individual task. And the BPE model would perform better because the compression allows it to learn at a faster rate -- i.e. the same amount of training computation spent on the BPE'd model gives you much more impact than computation spent on the byte level model.
In other words, the larger context window is the whole point. You get 2048 tokens. If you make it 2048 bytes, then you get a very limited view of the input text, which harms overall performance. But if you train it on specifically math problems, then of course it'll achieve superior performance, and not simply because it has an unscrambled view of the digits.
As I said before, this is like saying that JPG compression is harmful to our understanding of an image. But it's clearly not. The JPG may be composed of wavelets, but what matters is the overall signal -- and that signal is what GPT is being trained on (the understanding of language), not the individual characters.
This also explains why tokenization doesn't seem to affect performance across languages that much. Russian tokenizes into many more characters than English, yet GPT can still achieve pretty good performance on it. This isn't because the characters are scrambled, but rather because it's seen many more examples of English than Russian.
I think there is an issue in vocabulary size though.
If I'm correct in thinking that the OP is proposing that what Llama does ("Notably, we split all numbers into individual digits") explicitly this allows the model to treat a number as a sequence of digits so it can learn how math works.
This is especially important with very rare numbers. Take a number the GPT has never (or hardly ever) seen in its training data:
832408345770928764
The GPT-3 tokenizer tokenizes[1] that into:
83,24,08,345,7,709,287,64
To some degree this is forced to occur by the use of raw BPE encoding and the vocabulary size (175K in the case of GPT-3).
Now consider the string:
832408345770928764 + 37
The model presumably has learnt something like "if all tokens are in this area (where the area is "numbers" in the token-space) and they are followed by a + sign then we don't just append the string, instead we swap the last token for another one"
But of course this is insufficient in this case - it needs to learn carrying rules to also increment the next token. As is speculated in https://arxiv.org/abs/2212.10559, it's possible there's a relationship between the depth of the model and the length of chained rules it can learn, and because of the number of multi-digit tokens it has learnt these rules are unnecessarily complex, and incomplete.
If these tokens were instead single digits the rules would be much simpler, and it's possible the model could actually learn the real rules of math instead of the subset of semi-memorized things it has at the moment.
What about a tokenizer where the digits 0-9 just get the tokens 0-9, all other tokens are derived in the usual BPE manner (except that no token other than 0-9 is allowed to contain digits). Such a model wouldn't have a notable reduction in context size and should behave largely the same in terms of training speed and language tasks, but if sbierwagen is right it might be significantly better at math (and at least on an intuitive level this seems to make sense).
This is pretty much what LLaMA did, for what it's worth. Unfortunately there are so many other architectural and training differences that comparing the arithmetic ability of LLaMA and GPT-3 would not settle this debate.
> This is pretty much what LLaMA did, for what it's worth.
I don't think that's exactly accurate. The GP proposed:
>> What about a tokenizer where the digits 0-9 just get the tokens 0-9, all other tokens are derived in the usual BPE manner (except that no token other than 0-9 is allowed to contain digits).
The paper says:
> We tokenize the data with the byte-pair encoding (BPE) algorithm (Sennrich et al., 2015), using the implementation from Sentence-Piece (Kudo and Richardson, 2018). Notably, we split all numbers into individual digits, and fallback to bytes to decompose unknown UTF-8 characters.
I read this as sayng the a number like 1002 would be split into 1,0,0,2 and then represented by the tokens IDs that point to those digits. These are not the same things.
You mean because the token ids are in a different order? This is irrelevant to a transformer model, there is no inductive bias that similar tokens should have related token ids.
>Interestingly, the code FB provided doesn't seem to have any special handling for digits
I think you are likely wrong, but given neither of us are going to spend millions of dollars training two versions of GPT-3 we will have to agree to disagree. Meta seems to agree with me, since when they trained LLaMA they used one token per digit.
You'll be able to access millions of dollars worth of compute. It's how I got my start.
I love when I'm mistaken, since that's how science is pushed forward – we can't be certain we're right, only that we're not wrong yet. So it would be delightful if you formulate this into a testable hypothesis and falsify it yourself.
Well, it's certainly not the lowest level token - to the degree we can talk about tokens in our brains in the first place.
We can talk and think about such things as the shape of the letters, which it would take a Herculean effort for GPT-like models to learn, since it gets letters in a form where that information has been stripped away.
As pointed out by gerad above, we humans don't treat multi-digit numbers as one atomic token. We know 11 = 10 + 1. But if an AI model has no access to individual digits no matter how large the number is, then the task of doing simple maths is exponentially harder to learn.
> If you trained GPT specifically on arithmetic tasks
Sure but you'd have a lot of overlapping tokens with BPE, which doesn't help with convergence. GP is claiming it's specifically worse at arithmetic because of BPE which is true.
{kind=link}
This is the myth I was referring to. BPE compression may slow down training, but it doesn't follow that slower training is the reason for being bad at math.
If you trained GPT specifically on arithmetic tasks, you'd get superior performance to GPT-3, regardless of which tokenization scheme you'd use. But you'd destroy most of its knowledge about everything not-arithmetic.