quickjs [1] has native support for Cosmopolitan, is meant to be easily embeddable, and is included as part of the standard Cosmopolitan distribution. It looks like qjs also has patches for recent-ish versions of the Typescript compiler as well. Someone has made a nodejs-style project called txiki.js [2] using vanilla qjs. Maybe it would build with Cosmopolitan with some tweaking. But if you're thinking of packaging a whole browser engine like Electron that might be a Sisyphian effort.
Apparently there's also a data processing library for Nim called Arraymancer[0] that's inspired by Numpy and PyTorch. It claims to be faster than both.
Some people don't like systemd because it rolls a bunch of other functionality beyond 'just init' into a giant monolithic beast. The advantage is that distro maintainers are able to present an extremely usable and stable system like Ubuntu, Arch or any of the other mainstream distros. For most people that just want to use their computer to do regular stuff like browse the internet and edit photos and stuff, systemd or otherwise doesn't really matter because you pretty much never need to touch those parts of the system. Alternate init systems are for power users or people with particular constraints. For example, one of the reasons Alpine Linux is able to be so small is because it uses OpenRC instead of systemd.
Personally, I use a non-systemd distro because my computers all have tiny-sized HDDs by today's standards and I hate having to read a bunch of documentation every time I want to create a new system service. To me, it's easier to just write an ordinary shell script. I don't need all the ridiculous logging capabilities that systemd offers. Regular old plain text is enough for me.
I prefer system d because I also have a cloud VM where I use systemd to run a database and an account service online for the games I make. I found systemd to be pretty darn nice for that. basically a better supervisor and far less bulky than using Docker.
That being said, I almost never use (or even think about) systemd on my Linux Mint install.
Yes, for things like PATH.
But ASSIGN did more, you could essentially create a "device" (combining all ADD'ed things) that could be transparently accessed as such by other programs. It worked like a version of the Windows SUBST command accepting multiple arguments.
Yes, a lot like a union mount except that it was read only and easy to modify.
Assigns were often used for things that we today would stuff into an environment variable to represent an array of paths. Instead of an environment variable for setting the search path for shared libraries, on the Amiga you would just setup `LIBS:` and an application could find its libraries by opening `LIBS:MyFoo.library`. Similar story for $PATH. Amiga has `PATH:` which "contained" all of the executables in your path. Unlike unix style environment variables, assigns were system wide. (Amiga was a single user system.)
If it is indeed a union mount mechanism, then that's truly a remarkable feature. Reading the documentation makes it sound like something akin to an symbolic link but perhaps not in the actual filesystem; I still can't tell if it's implemented in the kernel/FS or just the shell (or to what extent the two are integrated). If it's just the shell then this seems to be a shining example of where the POSIX interface is holding us back. In Linux, they've tried to implement union mounts a number of times (as UnionFS, aufs, and OverlayFS) because it's almost too complicated to get right for Unix-style filesystems and you need a bunch of kernel-level code. Do you happen to know if it was possible to create the ASSIGNs programmatically? Does deleting/renaming files in the ASSIGN work like you'd hope?
Yes, it was indeed implemented at OS-level, you could point at the assigned name/alias from, say, a paint program and find the files/dirs you'd expect to see. Changes to files/dirs too worked as expected as far as I can recall (disclaimer: most recent Amiga experience -> 1994). It was also possible to create assigns programmatically with calls to the Amiga DOS library, see "dos.library/AssignPath" in http://amiga.nvg.org/amiga/reference/Includes_and_Autodocs_2...
NAME
AssignPath -- Creates an assignment to a specified path (V36)
SYNOPSIS
success = AssignPath(name,path)
D0 D1 D2
BOOL AssignPath(STRPTR,STRPTR)
FUNCTION
Sets up a assignment that is expanded upon EACH reference to the name.
This is implemented through a new device list type (DLT_ASSIGNPATH, or
some such). The path (a string) would be attached to the node. When
the name is referenced (Open("FOO:xyzzy"...), the string will be used
to determine where to do the open. No permanent lock will be part of
it. For example, you could AssignPath() c2: to df2:c, and references
to c2: would go to df2:c, even if you change disks.
The other major advantage is assigning things to unmounted volumes,
which will be requested upon access (useful in startup sequences).
INPUTS
name - Name of device to be assigned (without trailing ':')
path - Name of late assignment to be resolved at each reference
RESULT
success - Success/failure indicator of the operation
SEE ALSO
AssignAdd(), AssignLock(), AssignLate(), Open()
The profusion of Category-theoric abstractions and some of the more recent purely functional norms in Haskell are like the PhD-level version of `AbstractVisitorContextFactoryBuilder` which, aside from all the unnecessary cognitive load, lead to enormous dependency graphs of the npm variety.
Personally, I wonder if uniqueness types in languages like the sadly forgotten Clean (a close relative of Haskell) would have been better than the whole Monad/Arrow thing. All of that abstract theoretical stuff is certainly fascinating but it's never seemed worth all the bother to me.
On the other hand, in SML you get all the benefits of strong HM type inference/checking, immutability by default, etc, etc.. while also still being able to just `print` something or modify arrays in place. SML's type system isn't higher-order like Haskell's so its solution to the same problem Haskell solves with type classes isn't quite as elegant but otherwise SML is the C to Haskell's C++.
I find there are two main problems with monads in Haskell:
- Monad is just an interface (with nice do-notation, to be sure), but it's elevated to an almost mythic status. This (a) causes Monad to be used in places which would be better without (e.g. we could be more generic, like using Applicative; or more concrete by sticking to IO or Maybe, etc.) and (b) puts off new comers to the language, thinking they need to learn category theory or whatever. For this reason, I try to avoid phrases like "the IO monad" or "the Maybe monad" unless I'm specifically talking about their monadic join operation (just like I wouldn't talk about "the List monad" when discussing, say, string splitting)
- They don't compose. Monad on its own is a nice little abstraction, but it forces a tradeoff between narrowing down the scope of effects (e.g. with specific types like 'Stdin a', 'Stdout a', 'InEnv a', 'GenRec a', 'WithClock a', 'Random a', etc.) and avoiding the complexity of plugging all of those together. The listed advantages of SML are essentially one end of this spectrum: avoiding the complexity by ignoring the scope of effects; similar to sticking with the 'IO a' type in Haskell (although even there, it's nice that Haskell lets us distinguish between pure functions and effectful actions).
Haskell has some standard solutions to composing narrowly-scoped effects, like mtl, but I find them to be a complicated workaround to a self-imposed problem, rather than anything elegant. I still hold out some hope that algebraic effect systems can avoid this tradeoff, but retro-fitting them into a language can bring back the complexity they're supposed to avoid (e.g. I've really enjoyed using Haskell's polysemy library, but it requires a bunch of boilerplate, restrictions on variable names and TemplateHaskell shenanigans to work nicely).
Well said. This is exactly my gripe with Haskell monads. There are too many places where the hierarchy isn't uniform and there are a bunch of special monads like IO and List. It leads to the same ambiguous "is a" problem of complicated OO hierarchies and is one of the reasons they don't compose well.
The ironic thing is that these algabraic effect systems have a feel/control flow pattern that's quite similar to exception handling from the OO languages or interrupt handlers in low-level code.
It's much easier to just say "this piece of code is impure, it may do X, Y, and Z and if so then ..." than to try and shove everything ad-hoc into the abstract math tree. But then you lose the purity of your language and it's really awkward in a language whose primary concern is purity. That may be a reason why algebraic effects seem a bit more natural in OCaml.
I don't think there's a way to not use monads, because a ton of everyday things just work in a monadic way, things like lists, or statement sequences in presence of exceptions. I think it's wiser to admit and use these properties instead of ignoring them.
Ignoring maths that underlie computation when writing software is like ignoring math that underlies mechanics when building houses: for some time you can get by, but bigger houses will tend to constantly fall or stand a bit askew, and the first woodpecker to fly by would ruin the civilization, just as the saying goes.
Uniqueness types were a nice idea indeed. I suspect linear types (or their derivative in Rust) do a very similar thing: data are shared XOR mutable.
I recently read a blog post by someone who worked as a carpenter for a summer. He said he disliked the saying “measure twice, cut once” because actual carpenters avoid measuring as much as possible! For example, to make a staircase, you could try using simple trig to calculate the lengths of the board, angle of stair cut outs, step widths, etc. But that would all be wasted effort because you can’t actually measure and cut wood to sufficient precision. Instead, you need to just get rough measurements and then use various “cheats” so the measurements don’t matter, like using a jig to cut the parallel boards at exactly the same length (whatever it turns out to be).
Analogy to monads is this: yes, there are mathematical formalisms that can describe complex systems. Everything can be described by math! That’s literally its one job. But will the formalisms actually help you when the job you’re doing has insufficient achievable precision (eg finding market fit for a website)?
I think that the metaphor leaks badly. Finding market fit is like deciding on the general shape of the staircase. Execution of whatever design still needs the stairway to be strong and reliable all the same.
Writing code is a much more precise activity that cutting wood. Using "cheats" can get you somewhere, but due to the precise nature of the machine logic, the contraption is guaranteed to bend and break where it does not precisely fit, and shaving off the offending 1/8" is usually not easy, even if possible.
> But will the formalisms actually help you when the job you’re doing has insufficient achievable precision (eg finding market fit for a website)?
In my experience, this is exactly the problem Haskell's core abstractions—monads among them—help with!
What do you need when you're trying to find product-market fit? Fast iteration. What do Haskell's type system and effect tracking (ie monads) help with? Making changes to your code quickly and with confidence.
1. Make clean, well-factored code the path of least resistance.
2. Provide high-level, reusable libraries that keep your code expressive and easy to read at a glance despite the static types and effect tracking.
3. Give you guardrails to change your code in systematic ways that you know will not break the logic in a wide range of ways.
If I had a problem where I'd need to go through dozens of iterations before finding a good solution—and if libraries were not a consideration—I would choose Haskell over, say, Python any day. And I say this as someone who writes a lot of Python professionally these days. (Curse library availability!)
Honestly, Haskell has a reputation of providing really complicated tools that make your code really safe—and I think that's totally backwards. Haskell isn't safe in the sense that you would want for, say, aeronautical applications; Haskell programs can go wrong in a lot of ways that you can't prevent without extensive testing or formal verification and, in practice, Haskell isn't substantially easier to formally verify than other languages. And, on the flipside, Haskell's abstractions really aren't complicated, they're just different (and abstract). Monads aren't interesting because they do a lot; they're interesting because they only do a pretty small amount in a way that captures repeating patterns across a really wide range of types that we work with all the time (from promises to lists to nullable values).
Instead, what Haskell does is provide simple tools that do a "pretty good" job of catching common errors, the kind of bugs that waste a lot of testing and debugging time in run-of-the-mill Python codebases. This makes iteration faster rather than slower because you get feedback on whole classes of bugs immediately from your code, without needing to catch the bug in your tests or spot the bug in production.
As a bit of an aside, it's interesting that the CS (Haskell, mainly) descriptions of a Monad are much more complicated than the math.
Knowing a little bit of maths, but not much category theory, the wiki entry for Monads(Category Theory) is pretty clear. First sentence: A Monad is an endofunctor (a functor mapping a category to itself), together with two natural transformations required to fulfill certain coherence conditions. Easy.
Knowing a bit of programming, but not much Haskell, reading the entry for Monad (functional programming) or any blog post titled "A Monad is like a ...", it almost seems as if the author is more confused about what a Monad is than me. The first sentences of the Wikipedia article for example are a word-salad. With dressing.
From an outsider's perspective, it's almost as if a monad in functional programming is not a 1:1 translation of the straightforward definition of category theory, leading to an overall sense of confusion.
The formal definitions are straightforward enough, but the definitions alone don't really motivate themselves. A lot of mathematical maturity is about recognizing that a good definition gives a lot more than is immediately apparent. Someone without that experience will want to fully understand the definition, and fairly so -- but a plain reading defies that understanding. That is objectively frustrating.
> As a bit of an aside, it's interesting that the CS (Haskell, mainly) descriptions of a Monad are much more complicated than the math.
I actually do agree with this, though. I feel like monads are much simpler when presented via "join" (aka "flatten") rather than "bind"; and likewise with applicative functors via monoidal product (which I call "par") rather than "ap". "bind" and "ap" are really compounds of "join" and "par" with the underlying functorial "map". That makes them syntactically convenient, but pedagogically they're a bit of a nightmare. It's a lot easier to think about a structural change than applying some arbitrary computation.
Let's assume the reader knows abut "map". Examples abound; it's really not hard to find a huge number of functors in the wild, even in imperative programs. In short, "map" lets us take one value to another, within some context.
Applicative functors let us take two values, `f a` and `f b`, and produce a single `f (a, b)`. In other words, if we have two values in separate contexts (of the same kind), we can merge them together if the context is applicative.
Monads let us take a value `f (f a)` and produce an `f a`. In other words, if we have a value in a context in a context, we can merge the two contexts together.
Applicative "ap", `f (a -> b) -> f a -> f b`, is "par" followed by "map". We merge `(f (a -> b), f a)` to get `f (a -> b, a)`, then map over the pair and apply the function to its argument.
Monadic "bind", `(a -> f b) -> f a -> f b`, is "map" followed by "flatten". We map the given function over `f a` to get an `f (f b)`, then flatten to get our final `f b`.
It's a lot easier to think about these things when you don't have a higher-order function argument being thrown around.
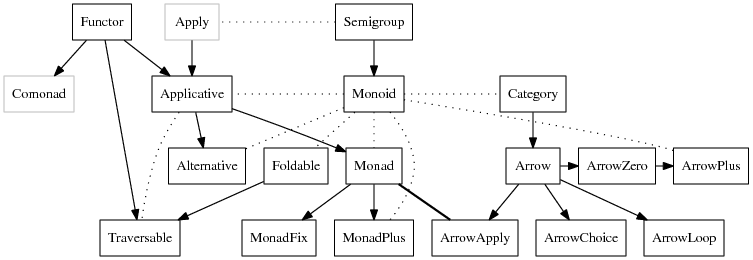
The problem isn't with the mathematical concept of monads, it's that Monad is a typeclass in a hierarchy along with other totally abstract category theoric classes introduced at different stages and people use them with varying levels of knowledge and ignorance so things are placed arbitrarily and there are a bunch of ambiguities. Just look at this [0] mess. Is that really what we want?
I believe the 'problem' that it solves is universal network transparency between pieces of anything. It's a library that can be used from basically any language that has a C FFI on any system with a C compiler to do IPC with anything else supporting same using a uniform and relatively simple API.
In addition, every closure is also a 'state container,' as it were. This is how some functional languages e.g. Erlang emulate mutation. A function holds the desired state in a closure and evaluates to a new function closure with updated state. It's also how a stateful object system can be trivially implemented in Scheme.
A few of pieces of the Erlang OTP infrastructure are actually just an elaborate mechanism to reintroduce global mutable state i.e. the process registry or Mnesia.
You can use closures to store state in Erlang, but generally state is kept by passing it through to further function calls.
I would say this makes Erlang mostly have explicit state, rather than saying Erlang is stateless.
Ets is implemented in C as global mutable state, but you could implement it in Erlang as a process per table (and a process to hold the list of tables) with no loss of functionality. You would send messages to fetch data or update data, etc. It's a performance and memory efficiency optimization to do it with C, of course.
It’s important to note Erlang’s global state tools are about controlled global state. The process registry is more elaborate than a simple naming scheme in say Python or Java but really not much harder to use. However that controlled registry allows the process registry to become multi-node with minimal or no code changes for the clients. It’s comparable in power to but far simpler than Consul or etcd for finding services. I view micro services as fairly equivalent to Erlang actors as they both reinforce that state encapsulation. The same idea goes for mnesia or ETS which are comparable in power to Redis.
Pure functional languages, aka Haskell or Idris or whatever, don't have this property. A closure closes over values, and thus is a value, no state mutation involved.
Of course, your point about complex mechanisms to reintroduce mutation into specific contexts stands (usually via monads) but those are a very different Kind of object then the functions.
In my state, most of the programs the community colleges offer are aimed either at credential acquisition or for transfer to a university; there are no four year programs. However, many of the teachers at these schools are also PhDs moonlighting from local universities where they teach upper-level subjects and the community college offers a handful of classes that are at the 300/junior level for certain subjects. The thing that's really missing from the community college curriculum that would shake up the university pricing model is the ability to get a Bachelor's degree. At least in my state, it doesn't seem like there would be too much of a stretch to accommodate the additional educational resources it would require. Some people go to a university because they want access to first-class facilities, professors, student networking, and the like. In fact, the tuition at my local university more than doubled after they managed to get their basketball team into the NCAA Final Four one year. But many people don't care about this kind of thing; they just need their 'certificate of passage of this particular social ritual'.
Comparing tuition at Cabrillo College (community college for Santa Cruz, CA) and SJSU (California State University in San Jose), it looks like a "normal" course costs $574 at the bottom-tier 4-year university vs $230 at the community college. If you take 2 or fewer classes in a semester at SJSU (as a full-time student, you're supposed to take 5), tuition falls nearly in half to $333 per class.
$6000 tuition per year is high enough to be prohibitive for some people. But those people are the focus of intensive recruitment and financial aid efforts by universities all up and down the hierarchy of status. That isn't the first place I'd look if I were seeking to answer "why aren't more poor people going to college?"
{kind=link}